
Autor: Armin Schmid, Product Marketing Ingenieur Epson
Introduction & Motivation #
Do the following situations not sound familiar to you? You are busy with an important task and are suddenly startled by an alarm sound. A device reports a problem, but only a encrypted error code is shown on a display. An operating manual is usually not available and therefore troubleshooting turns out to be difficult.
Another example, in a hotel, the fire alarm goes off at night. The guests do not know the reason for the alarm and excitedly searches for the information on the escape routes of the building. Alarm tones that are triggered in dangerous situations can quickly cause people to panic and make wrong decisions if the cause of an alarm is not immediately apparent.
In both examples, a voice output with dedicated instructions for everyone involved could be very helpful. Read here how applications learn to talk.
A barrier-free use of products by visually impaired people can also be ensured by voice output. Eye contact with the respective device is no longer necessary, which significantly increases safety when driving, for example. Similar alerts can also provide valuable services in manufacturing facilities. In addition, voice output can significantly simplify the operation of increasingly complex evices. Applications with bidirectional communication go even further, so they can not only “talk” but also “hear”, such as Alexa, Siri and Co. However, voice output is often sufficient. This has the advantage that the hardware and software costs are significantly lower and no complex infrastructure with an internet connection is required.

Interested in this topic? Take the chance to meet Epson and our experts on this topic on Electronica next week! Please give us a short request through our web from to fix an appointment. Link to web form.
Elements of Voice Application Development #
Voice output via speaker or buzzer #
The perceived quality of a text that can be achieved and a listener can hear is the most important decision criteria for a voice output function. However, this not only depends on the selection of the electrical components of a design, but also on the possible mechanical dimensions of the application, the entire acoustic design. There are also other criteria such as the volume to be achieved. The main criteria for voice output via buzzer or speaker are shown in Figure 1.
 The mechanical dimensions of a product are determining the extent to which a speaker or just a buzzer can be installed. For cost-optimized applications, a piezoelectric buzzer will usually be chosen. However, if the focus is on voice quality and a higher sound volume, electromagnetic buzzers or speakers are unrivaled. In order to offer the best flexibility, Epson’s voice output solutions support all four configurations shown in Figure 1. In particular, the high-quality voice output via buzzer is a unique feature of the Epson solutions.
The mechanical dimensions of a product are determining the extent to which a speaker or just a buzzer can be installed. For cost-optimized applications, a piezoelectric buzzer will usually be chosen. However, if the focus is on voice quality and a higher sound volume, electromagnetic buzzers or speakers are unrivaled. In order to offer the best flexibility, Epson’s voice output solutions support all four configurations shown in Figure 1. In particular, the high-quality voice output via buzzer is a unique feature of the Epson solutions.
The frequency range of human voice is in the range of 200 Hz to 500 Hz. Due to its system, a buzzer works at higher frequencies in the range of a few kHz. In order to reproduce spoken texts as realistic as possible, also due to the limited playback bandwidth of buzzers, the Epson voice output solutions offer a corresponding optimization of voice.
Easy generation of voice/audio data from text files #
Until now, the respective text had to be recorded in every desired language for a voice output. This means: A recording studio and professional “native” speakers had to be booked – an expensive and time-consuming solution. In order to reduce development time and costs drastically, Epson has developed the ESPER2 Voice Data Creation PC Tool. With this PC-based Text-To-Speech development environment, high-quality audio files can be created currently in up to 12 different languages.
For this purpose, pre-formulated sentences can be imported into the tool as text in CSV format or entered directly. The tool generates a language file. For the correct and natural pronunciation and intonation, ESPER2 also analyzes the syntax of the texts, among other things. The pronunciation of product and proper names or an own neologisms can be brought into the desired form with the editing function. As a result, the quality of the generated audio files is almost indistinguishable from the spoken word of a human being.

If voice and audio data are already available in WAV format, they can also be easily imported into the development environment in order to link them to the files generated by ESPER2. Sets can be exported from the tool as an Excel download in CSV format for further processing as well.
Language support „Around the world“ #
ESPER2 currently supports 12 languages: American and British English, French and Canadian French, German, Italian, Russian, Spanish and American Spanish, Chinese, Japanese and Korean. In order to depict language-specific features, the female voice can be adjusted in pitch and voice speed. However, the tool does not have a translation function. The text must be entered in the desired language in the ESPER2 Text editor.
High voice quality and small memory requirements #
For efficient output and storage of voice data, ESPER2 uses Epson’s own EOV format (= Epson Original Voice). Compared to the standard compression ADPCM (Adaptive Differential Pulse Code Modulation), EOV reduces the file size by a quarter with high voice quality and the same sampling rate of 16 kHz and by two thirds with a reduced sampling rate of 8 kHz. The memory structure consists of the voice and audio data of the .eov file and ID numbers for controlling the voice output function. So that developers can keep track of a large number of sentences in several languages, they can assign a uniform ID of the lookup table to a sentence in different languages. When this ID is called, the sentence can be played in different languages.
In order to save further memory space, often repeated formulations can be connected with further statements using a slash (/). Here is an example:
ID number 1: “The temperature is /30 degrees.”
ID number 2: “The temperature is /31 degrees.”
ID number 3: “The temperature is /32 degrees.”
The voice data generated here are: “The temperature is” and “30 degrees”, “31 degrees”, “32 degrees”.
Epson Solutions #
Epson Single Chip Solution: Voice/Audio output using 32-bit ARM Cortex M0+ MCU #
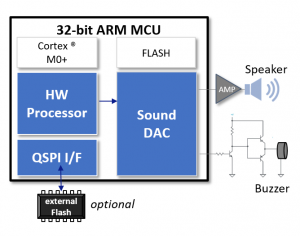
Figure 2 shows a single chip solution based on the 32-bit ARM Cortex-M0+ microcontroller family on which the final application is running as well as the storage and output of the generated voice data is executed. The voice and audio data can be stored both in the internal memory and optional in an external flash memory. Currently two 32-bit ARM Cortex M0+ microcontrollers S1C31D50, S1C31D51 and S1C31D41 are available. In addition to the Core-CPU, the components offer an integrated voice and audio hardware processor (HWP) and a sound DAC. This enables the simultaneous playback of two channels (e.g. voice and music) whose volume can be controlled independently, each with a sampling rate of 15.625 kHz. This represents another unique selling feature of the Epson voice output solutions.
Typically, the music volume is reduced when voice output start. The pitch and voice speed are controlled by a special HW audio processor, the speed is adjustable in 5% increments between 75% and 125%. To play back the generated voice and audio data, only their IDs are written to a register in the hardware processor. Special program code for linking the sound files is therefore not necessary and apart from writing the IDs, no further CPU resources are required, i.e. the CPU can take over other tasks independently of the voice output without restrictions or go into sleep mode.
The S1C31D51 also supports voice output via a piezoelectric buzzer or an electromagnetic buzzer. In order to support more customer-oriented functionalities or personalized text, the single chip solutions could include a microphone connected to the AD converter input. If required, Epson will supply sample code for such a software solution.
Discrete Epson Solution: Voice/Audio output using dedicated Speech IC #
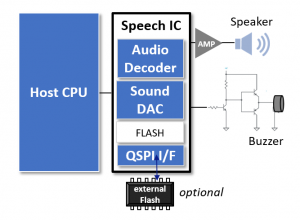 There are often good reasons not to change the application CPU despite the functional expansion with a voice output. A discrete solution with an existing host microcontroller in combination with a component from the Epson speech IC family (S1V3xxxx ) is the ideal solution for such purpose as shown in Figure 3. This concept only requires a free SPI interface. Even with the discrete solution, the voice and audio data can be stored both in the internal memory and optional in an external flash memory.
There are often good reasons not to change the application CPU despite the functional expansion with a voice output. A discrete solution with an existing host microcontroller in combination with a component from the Epson speech IC family (S1V3xxxx ) is the ideal solution for such purpose as shown in Figure 3. This concept only requires a free SPI interface. Even with the discrete solution, the voice and audio data can be stored both in the internal memory and optional in an external flash memory.
The first device in the series, the S1V3G340, offer one audio channel, meaning it can output either voice or music. However, future speech ICs will support the playback of two channels whose volume can be controlled independently.
Epson Voice/Audio playback solutions and Evaluation tools #
A number of Epson evaluation tools are available for customers. The quality of the voice output via a speaker can be tested with both evaluation boards S5U1C31D50T1200 and S5U1C31D51T1100. If the buzzer board S5U1C31D51T2100 (Figure 4) is used in combination with the S5U1C31D51T1100 it is possible to test the voice/audio quality output using a piezoelectric or electromagnetic buzzer too. Several voice/audio examples in various languages are already installed on both evaluation boards S5U1C31D50T1200 and S5U1C31D51T1100 to get a first impression about voice/audio playback quality just by powering the evaluation board and connecting a buzzer or speaker. The desired language can be selected via a DIP switch. After installing and licensing the free ESPER2 software, it is possible to create own sentences, modify the text as desired and upload them to the evaluation board. An evaluation board for the S1V3G340 as shown in Figure 5 is available for the discrete solution.
Further Information on the Web #
Both official YouTube videos give a good overview of the achievable voice quality and how easy system integration can be done:
https://youtu.be/j-t7pqkzrSg, https://youtu.be/_MfX8mu9k6g
Outlook
Due to the simplicity of the system integration and the variety of supported playback modes, there are no limits to the variety of supported applications. With the current available or future voice audio solutions from Epson, you can bring your applications to “Talk” with you with a minimum amount of effort.


